Making RL Fast
For Olmo 3, I was put in charge of our post-training infrastucture. We made the decision to move from a synchronous RL setup to an asynchronous one to enable us to scale. In doing that work, I was fortunate enough to find a series of optimizations which made our RL setup 4x faster. As we used roughly 250k H100 hours running RL on Olmo 3, these optimizations saved us approximately 750k H100 hours (~$1.5M) at current market prices. These changes were detailed in the paper, but I wanted to write more about them here.
There were three primary optimizations:
- Continuous batching.
- Inflight updates.
- Better thread synchronization.
Continuous batching (+11% throughput)
For Olmo 2, our post-training code used a synchronous RL approach, in which the actors and learner all operate in lockstep. For every training step, we load a batch of prompts that we want to send to the actors to complete, and we split the batch into N chunks (where N is the number of actors), sending each to a different actor. Then, our learner waits for all the actors to complete their generations. When they're all done, the N completion chunks are reassembled into a batch of completions which is trained on.
Such a synchronous RL setup is difficult to optimize and leaves a lot of performance on the table. It does what
is known as "static batching." In LLM inference, due to variable sequence length, there's a natural tendency towards
inefficiency. In traditional ML inference (say: you're running inference on a ResNet that is trying to classify MNIST),
there's no notion of sequence length, so all you have to worry about is your batch size. To efficiently run inference,
you'd fill your GPU with a sufficiently big batch
of examples and be done. With LLM inference, due to variable sequence length, this is inherently inefficient. If you
follow the naive approach, you'll waste (max_sequence_length - mean_sequence_length)/max_sequence_length of
your compute. On Olmo 3, we had an average generation length of 14k, and a maximum of 32k, so we would have
wasted 54\% of our compute with static batching. See the diagram for an illustrated example.
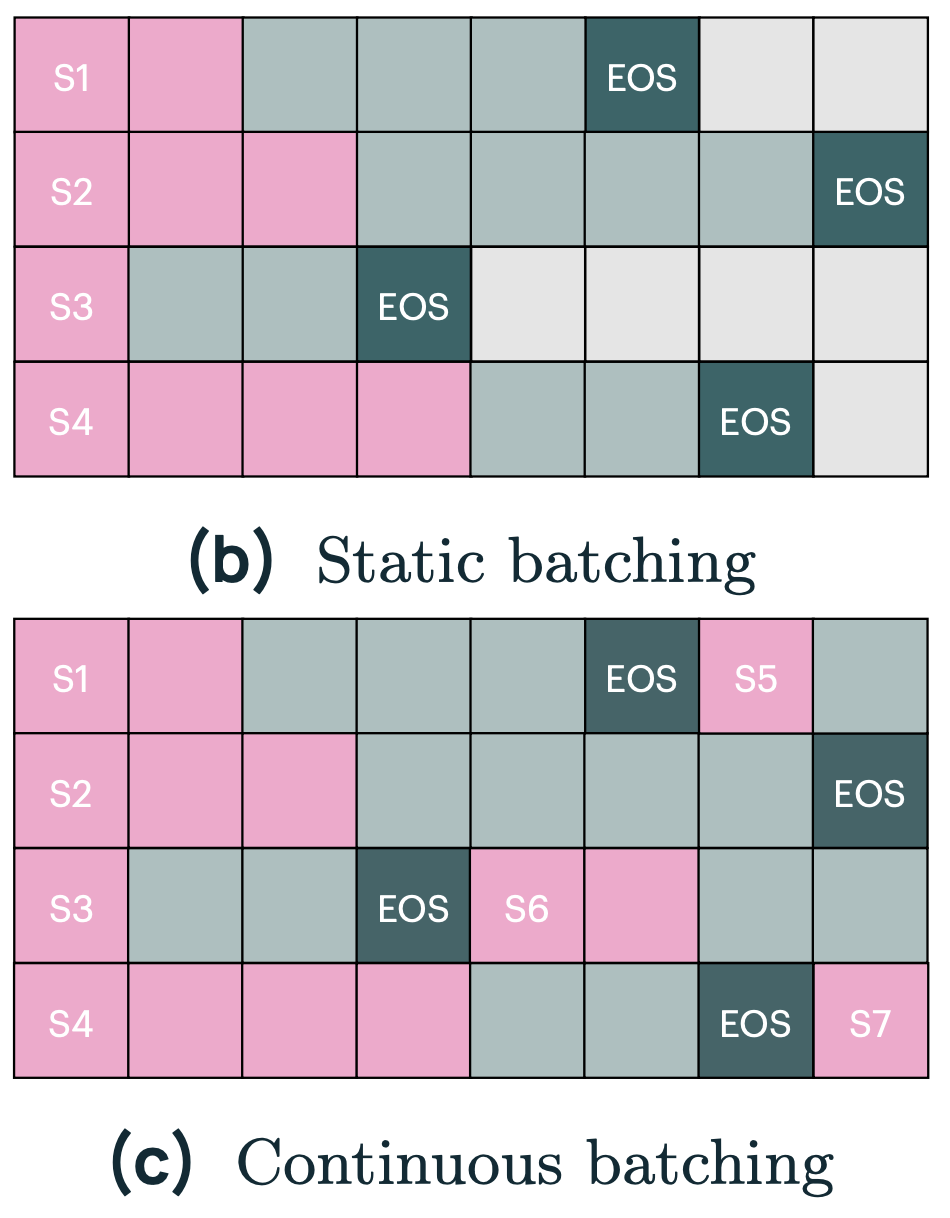
Instead, to optimally use your GPUs, you should be streaming examples in and out of your GPUs as previous completions finish. This is called continuous batching, where you constantly enqueue new generations as each one finishes. Continuous batching is how most LLM inference servers operate, so it wasn't that difficult to implement, but it required refactoring our codebase to support the new streaming architecture.
(I made ChatGPT make the original version of this image in Tikz. It was remarkably difficult. The LaTeX is available if you care to see how I tortured ChatGPT.)
Inflight updates (+117% throughput)
The major disadvantage of asynchronous RL is that it makes the actors more off-policy from the learner, i.e. the learner will be training on the current version of the model, but the actors might have generated the completions with an older version of the model. To avoid this, the synchronous version of the code would synchronize the actor weights after every training step. In the asynchronous setting, what this looks like is: each actor finishes all of their enqueued generations, stops accepting new prompts to their queue, updates their copy of the weights, and then resumes processing. Note, however, that this is exactly equivalent to the static batching case above, and introduces the same idleness problem!
Instead, we implemented PipelineRL, and only pause generation, instead of waiting for all completions to finish before updating the weights. By doing this, we avoid draining the queue, and keep our nice continuous batching performance, keeping our GPUs humming. This enables a significant increase in throughput: up to 2x faster in my experiments with the same resources, without hurting accuracy.
It is, however, a bit weird. Note that we pause partway through completing a generation, and then resume it with updated weights. We don't invalidate the KV cache! This means that we are using the KV cache calculated from an older version of the weights. It works fine, and can be justified with a handwavy epsilon-delta proof as a neural network is the composition of continuous functions, but it's a bit weird. Empirically it's fine, though, and it's hard to argue with a 2x speedup.
Better threading (+39% throughput)
Finally, after all these sophisticated changes to our RL pipeline, we ran headfirst into Amdahl's law. As we made our actors more asynchronous, the synchronization points become more of a bottlenck. In particular, coordinating the actors, and specifically, the weight sync, was a bottleneck.
To fix this, we had to completely decouple the actors, allowing each one to start and stop by itself, without waiting for the rest of the actors to finish their syncs as well. Similarly, we make a large number of optimizations that were not machine learning specific, and were centered around efficiently using the CPU. For example, our initial implementation of continuous batching, for instance, was slower than static batching until we adding a background prefetch thread to our actors that constantly refilled the inference queue.
Decoupling the actors was a pure systems change that affected how we synchronize the learner and the actors. The idea is that if you have N actors and need to do a weight broadcast, the naive way is something like this:
- Ask them all to stop (
for i in range(num_actors): actors[i].stop()) - Send the weight update to each one in turn (
for i in range(num_actors): actors[i].update_weights()) - Restart inference on the actors (
for i in range(num_actors): actors[i].start()).
In pseudo-code:
for i in range(num_actors):
actors[i].stop()
for i in range(num_actors):
actors[i].update_weights()
for i in range(num_actors):
actors[i].start()
If we do this, we have a bunch of synchronization points which kill performance in distributed systems, as the actors have to wait for all of the stragglers to finish.
Instead, we can have each actor operate independently and have each actor start/stop independently:
for i in range(num_actors):
actors[i].stop()
actors[i].update_weights()
actors[i].start()
Of course, we run this concurrently, so all the actors are doing this simultaneously. So perhaps something closer to:
async def update_weight(actors: list[Actor], actor_index: int):
actor = actors[actor_index]
await actor.stop()
await actor.update_weights()
await actor.restart()
await asyncio.gather(*(update_weight(actors, i) for i in range(num_actors)))
The main bottleneck now is that we have our learner broadcasting the weight updates, which is inherently sequential. We could move to an asynchronous approach like Cursor did for Composer 2, where the weights are written to disk, but we haven't found the weight broadcast to be a bottleneck in practice.
Here's the table from the Olmo 3 paper showing our results.
| Model | Tokens per second | MFU | MBU | Notes | Commit |
|---|---|---|---|---|---|
| qwen2.5-7b | 881 | 0.30% | 12.90% | Baseline before any major changes | 564f8a4 |
| qwen2.5-7b | 975 | 0.33% | 14.29% | plus continuous batching | ab90d5a |
| qwen2.5-7b | 1358 | 0.46% | 19.89% | plus better threading | e320ff0 |
| qwen2.5-7b | 2949 | 1.01% | 43.21% | plus inflight updates | e320ff0 |
Lately, I have been writing on my newsletter.