Papers I've read this week (March 4th, 2023)
I’m going to try to write a weekly summary of the most interesting papers I’ve read that week. I’d love to hear what papers you’ve been reading, if you agree/disagree about my conclusions for each paper, and/or suggestions for what papers I should read next!
Scaling laws for routed language models
I used to work with Aidan, and way back in 2021, he was insistent that LLMs were the future of AI. I thought he was crazy. In ‘22, he also insisted that conditional routing models were the future. Given how right he was about LLMs, it’s probably worth paying attention to conditional routing models.
The paper provides a great general overview of how routing networks work and performance comparisons (in terms of negative log likelihood over a validation dataset) for the 3 most common routing techniques (sparse MoE, non-parametric HASH, RL routing).
The authors trained a large number of conditional routing networks, and fit scaling laws to the results; they find that all 3 techniques follow the same scaling laws, with RL routing doing quite well. I’d be curious to see how much effort has been put into improving RL routing; I suspect that it could be improved significantly.
The authors observed the following results:
- Routing improves the performance of language models across all sizes and variants attempted
- Training a Routing Network with RL is of comparable effectiveness to state-of-the-art techniques.
- The performance of all Routing Networks is accurately described by scaling laws in the number of experts and in the underlying dense model size.
I was surprised at how similar the performance of the various techniques was. The data was quite nice, with little variation. The scaling laws seem to fit the data quite nicely.
One interesting result was that routing helps significantly more when the model is smaller. I found this surprising; my intuition is that routing should always help. They found that this was the case across all models, and that routing helped less as the models grew.
The paper ends with recommendations, which I found really useful:
- Use routing for models with less than 1.3B parameters
- S-Base is a good, default routing algorithm (defined in the appendix of their paper).
- Target using E in {64, 128} experts.
- Use K = 1 experts; route layers with a frequency between 0.5 & 1; lower frequency reduces performance.
Internet explorer
In this paper, the authors create an agent which dynamically explores the internet, running text queries to find images to use for self-supervised training. While seemingly designed to directly antagonize Yudkowsky, the paper is extremely interesting, and presents, to me, a potential future direction for AGI research. As Chinchilla showed us, LLMs could massively improve with more data. Having agents dynamically exploring the internet is one excellent way to get more data- especially if they’re able to adaptively learn over time and prioritize images accordingly.
In the paper, they train a model to learn representations of images based on MoCo-v3. They query Google Images for new images, ranking the query results by similarity to the target dataset, assigning a reward to the new images:
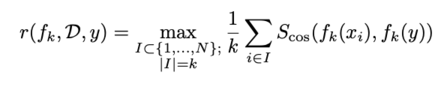
Here, S_cos is the cosine similarity, f_k is the image encoder, D := {x_i} is the target dataset, and y is the new image to evaluate, and they evaluate over the k closest neighbours in the target dataset (where “closest” is determined by the encoded representation).
They create the queries for Google Images by sampling them a static vocabulary dataset. They estimate the reward associated with the query using a Gaussian process regression. I’d be really interested to see a fancier query generation process. One idea that comes to my mind would be using RL to train a LLM to generate queries in a manner similar to what’s done in RLHF/RLAIF, i.e. use an RL algorithm like PPO to finetune a pretrained LLM to maximize reward. This would require much more compute, however.
LLaMa
I’ve been digesting the LLaMa paper that Facebook released this week. It was very interesting to see the performance increases they got despite the size decreases. Their 13B model outperformed GPT-3 on a number of benchmarks, and their 65B model was competitive with Chinchilla-70B and PaLM-540B (!).
I did find it incredibly frustrating that they stopped training when they did; their loss curves are all looking pretty far from convergence, and I’m curious to see how much the models will continue to improve:
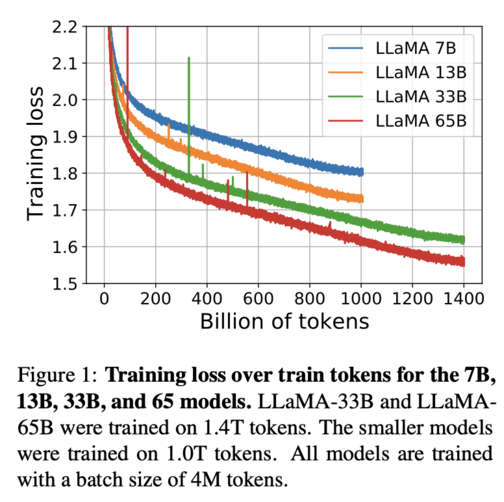
I wish that they had just left it training.
My biggest question about the paper is that it’s not clear what caused the improvements. They discuss a few major changes compared to GPT-3, which their model is based on:
- They only use publicly available data, but it’s unclear what exactly the filtering steps are. I wish they’d open source their dataset (or at least, the code to clean it).
- They normalize the input of each transformer sub-layer, rather than the output.
- They use the SwiGLU activation function, as PaLM did, with a slight dimensional difference compared to PaLM.
- They use Rotary Embeddings.1
There was no ablation study, unfortunately. If I can scrounge up the GPUs, I’m tempted to do my own ablation based on nanoGPT. LLaMa also uses FlashAttention, which I suspect will become the default attention implementation used in LLMs going forward.
Anecdotally, it seems like performance with the default parameters isn't great (unless you're writing erotic stories). However, it hasn't been tuned (RLHF/SFT), so maybe that would make a difference? With some modifications, performance is apparently pretty good. This lends strength to my hypothesis that the paper was rushed out in response to the LLM gold rush we've seen since ChatGPT was released. The paper, while strong, would be much stronger with a few more changes (ablation, more details, slightly more polished code), in a way that doesn't make sense for the omissions to be strategic.
Facebook benefits when open source LLMs get better in a way that OpenAI/Anthropic/Cohere/etc. doesn't, so they should want to do ablations and other scientific work to advance the field. The fact that they didn't include this makes me think that they wanted to get the paper out the door as soon as possible- probably to avoid the chance of being scooped with an even larger, better, model.
-
I haven’t seen a great ablation study comparing various embedding schemes. This is on my list of experiments to do once I can scrounge up GPUs. ↩
Lately, I have been writing on my newsletter.