A step towards self-improving LLMs
There's a Substack version of this post, if you prefer that over my amateurish artisan HTML.
If I look at GPTs/LLMs, two of the biggest problems I see with existing techniques are:
- We need our models to be able to generate data by themselves, i.e. we need a recursive self-improvement loop. AlphaZero is the shining example of what’s possible here.
- We need our models to be able to operate in new domains without requiring massive amounts of existing data. CLIP provides an option here, as does Internet Explorer (the paper, not the browser).
- Auto regressive sampling. It’s slow, suboptimal.
I have ideas for how to tackle #1, so I’ll focus on that here.
There are other issues facing LLMs, such as:
- Increasing the length of the context window
- Figuring out how to train larger models
- Figuring out how to train more efficient models (less parameters, less data, less energy)
- Factual accuracy
- Mitigating attacks that convince LLMs to exhibit harmful behaviour (”red-teaming”), e.g. prompt injection
I think these are fundamentally engineering problems that we’ll be able to figure out iteratively. For instance, context length has seen a lot of progress with subtle algorithmic improvements; if we combine those changes with the many arcane engineering optimizations that are out there, I think we’ll get to a point where context goes to 64k tokens or more, at which point we’ll be deep in the saturating point of the sigmoid. Or for factual accuracy- I think that retrieval will largely solve that once it’s incorporated into most models.
However, I’m probably wrong, and could very well end up writing a version of this post in 2034 talking about how the biggest problem facing AGI is prompt injections.
A path towards recursive self-improvement
GPTs work very well in one specific context: they are very, very good at finding text that is likely to follow other text in a way that appears natural to humans.
What they don’t do is come up with text that they haven’t seen before. Kinda. What they’re doing when we sample from them now is predict what they’ve seen during training. Sometimes these predictions produce text that hasn’t been written before (this can occur often, due to the combinatorial nature of token sampling). When this happens, it’s a happy accident. The model isn’t trying to select text that is novel or that accomplishes any goal other than following the preceding 2048 tokens (or whatever the context length is).
The obvious exception is when models are finetuned using RLHF. In RLHF, the models are explicitly trained to optimize a reward signal. In RLHF, the reward signal comes from a model trained to predict human feedback. Basically, humans are asked to choose between two samples of text, and then a model learns to predict which one is preferred.
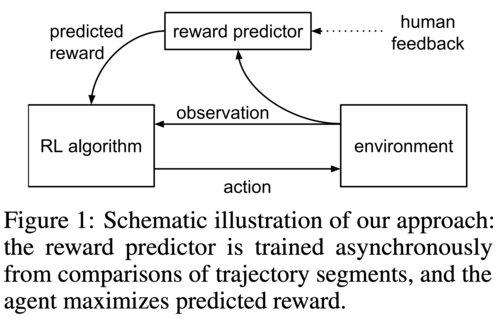
Why does this matter? Predicting the next token works pretty well! And maybe we’re all just stochastic parrots? It matters because the biggest impediment to improving our models right now is the lack of data. The scaling law papers (Chinchilla, OpenAI) consistently point to the fact that we need to scale up the datasets we train LLMs on.
For instance, Chinchilla predicts that we’ll need 11 trillion tokens to optimally train a model the size of PaLM (i.e. 540B parameters). If we want to push past PaLM to a model with 1 trillion parameters, we’ll need 20T tokens.
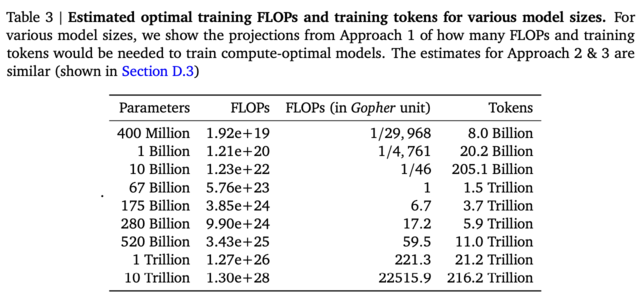
That’s a lot of data. That’s so much data that it’s not clear that we can get that from existing sources. nostalgebraist argues that 1) we’ve basically exhausted the available data in structured domains like coding and 2) it’s starting to look like we’re running out of general-domain data. I find nostalgebraist compelling; the only counterargument I could see is that private data sources might be a rich vein of tokens, but I don’t see a clear path to getting access to them.
This lack of data is unfortunate because, according to Chinchilla’s scaling laws, we could see another ~8% reduction in training loss (1.93 → 1.77, delta of 0.16 in loss) for if we had infinite data while changing nothing else about Chinchilla. That’s a pretty substantial improvement when you consider that the improvement from Gopher to Chinchilla was only 2.9% (1.99 → 1.93, delta of 0.06 in loss), not to mention the fact that our models are already quite good— able to trick Google SWEs into believing they’re sentient, and scaring the Yud.
More data
The clear implication is that we need way more data! Our models are desperate for data. They’re lying on the beach gasping for more data to quench their ever-growing thirst.
But where will the data come from?
If we can scrape it we should. It’s not clear how much there is left to scrape. Especially at the largest research institutions like OpenAI, Google Brain, and DeepMind, I’m certain that they have teams of engineers working on scraping all possible data. There is some possibility to automate this process; the excellently named Internet explorer paper presented a model which crawls the web to get additional data to augment it’s dataset. Although letting a nascent AI loose on the internet would make Eliezer cry, it could be an excellent source of data, especially if one incorporates some sort of reinforcement learning style feedback loop to continually improve the manner in which the model searches the web.
The data problem is compounded by the fact that high quality data really matters. Experiments consistently show that deduplicating data increases performance substantially (https://arxiv.org/abs/2205.10487, https://arxiv.org/abs/2107.06499). Basically, I’m not convinced there is a lot more high quality data. Two exceptions might be commercial data (e.g. internal corporate documents), and all copyrighted text. But it would be extremely difficult to get access to either of these corpora.
Generate data
The solution to me seems to be self-evident: we should generate our own data. There has been some work about training LLMs on data they have generated (https://arxiv.org/abs/2210.11610, https://arxiv.org/abs/2212.08073). There are a few different techniques that seem promising here.
In Huang et. al, they use Chain of Thought (CoT) reasoning to generate additional data. Given a dataset of questions, they sample N answers that use CoT to generate an answer. At the end, they ask “The answer is “ and get an answer; they then find the majority answer and choose all texts that return the same answer as the most common answer, using this to generate additional data. In practice, there’s no reason to questions, although that is a particularly straight forward problem to apply this to; one could imagine, say, embedding all of the generated answers, clustering them, and keeping the answers in the biggest cluster, or employing RLAIF like Anthropic did in the Constitutional AI paper to select the answers to keep.
Anthropic employed a similar approach as the CoT reasoning in the Constitutional AI paper.
Another option is to use RLAIF (from Constitutional AI) to generate data. In this,
Throw compute at the problem
Yet another line of research involves throwing compute at the problem. We know that we can use a variety of techniques to soak up compute and improve outcomes. For instance, ensembling is a classic ML technique that strictly improves model performance. Given that we are already at the extreme limit of what’s possible to compute with transformers, it is almost certainly not possible to naively ensemble LLMs.
However, what we can do is use compute to apply search on top of our existing model outputs. If we can find a policy improvement operator, i.e. a function T that takes an existing distribution over tokens, π, and returns a new distribution, T(π), which improves our loss, then we can use T to improve our model. Some candidates:
- Best-of-n
- Beam search
- Policy-driven search
“Best-of-n” (https://openai.com/research/measuring-goodharts-law) is a technique similar to ensembling in which we sample from our model N times, and use the sample with the highest score according to our objective function. This performs remarkably well (outperforming the RLHF model in the WebGPT paper(https://openai.com/research/webgpt)), is simple to implement, trivial to analyze mathematically, and trivially parallelizable, but makes inference N times more expensive. If I were OpenAI, I’d be caching the results of queries to their models and doing this for repeated queries.
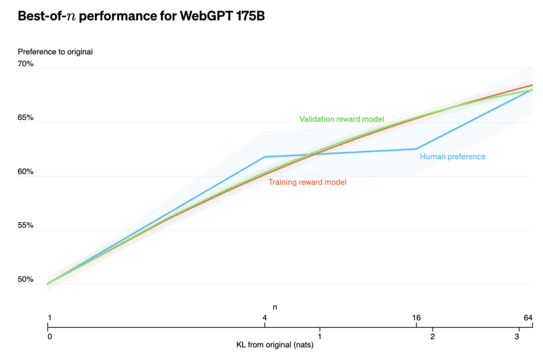
In the WebGPT paper, the authors found that best-of-16 resulted in an improvement in human preferences of 5% (60% → 65%), while going from 13B parameters to 175B parameters resulted in an improvement of 10% (~47% → 57%) (results from eyeballing graph, not precise).
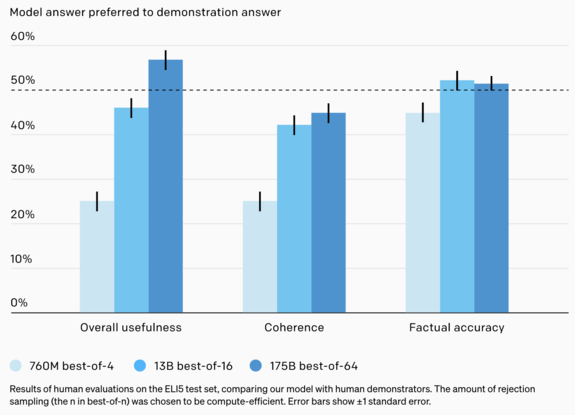
Given that both charts appear to be seeing roughly linear improvements, and both models increase in cost roughly linearly, it seems to imply that a best-of-64 13B model would be better than a best-of-4 175B model, while having roughly the same cost in terms of compute. Given that the 13B model should fits on a single GPU (maybe 2 GPUs?), this would substantially lower the overall compute of the system.
Another improvement operator is a NLP classic: beam search! In beam search, one performs a breadth-first search over the model outputs, with finite depth and width of the tree (e.g. it only keeps N successors at each level of the tree, and searches to a depth of M levels), with the final result being the sequence with the maximum objective score (typically log-likelihood).
While a number of the LLMs do use beam search1, they don’t appear to report performance numbers, so I’m unable to include a comparison of how much it matters.
A concern is that beam search still lowers diversity, as it constricts the difference in tokens; this is especially problematic for byte-level tokenizers, like BPE, as the individual tokens might vary significantly. Sander Dieleman wrote about how strategies like beam search are "the culprit behind many of the pathologies that neural machine translation systems exhibit”.2
The final candidate (or family of candidates) for the improvement operator is an option that I find very exciting: learning an algorithm to search the token tree. The idea is that we could do something like AlphaZero which would learn a policy + value function.3 This would also allow us to change the reward function if we wanted to, rather than just using the standard log-likelihood. We could, for instance, directly train the reward function on human data. If you’re serving data to millions of users per day, you could just directly run RL on that, which is the case for the myriad of chat bots on the market today (Bing, ChatGPT, Claude, etc.).
Discussion of beam search diversity
-
Examples include: GPT-{2,3}, which uses it during decoding for text generation, BERT, for language understanding tasks, T5, and XLNet. ↩
-
Sander’s post is great. I was struggling to understand why beam search isn’t used more in practice, and his post did a great job helping me understand why. ↩
-
Perhaps using MuZero with a smaller model as the recurrent function to save on compute. ↩
Lately, I have been writing on my newsletter.